INSIGHTS

Keller Maloney
Unusual - Founder
If 100 people ask the same question of a search engine, they all get the same ten blue links. If 100 people answer the same question, you get maybe five or ten different answers, which is the whole premise of Family Feud. If 100 AI models answer the same question, you get 100 different answers, each one personalized to the person asking.
That's the physics underneath every AI conversation, and it's incompatible with the measurement framework the industry has been building on top of it.
"Share of voice" is meant to describe how often a brand appears in AI answers. It's computed by taking a hand-picked set of prompts, like "What's the best CRM?", running those prompts through AI systems, and counting how often the brand is mentioned in the response.
Share of voice has quietly become the core metric for AI brand tracking. Brands are launching PR campaigns, commissioning content, and rebuilding their websites to move the number up.
It's possible to move that number, but it won't increase pipeline or market share. This article contains five reasons why.
The problem with tracking "share" of anything
The prompt set is constructed by hand
Share of voice is a fraction: the number of times an AI mentions your brand, divided by the total number of prompts you picked. The denominator is a list of prompts, and the accuracy of the metric hinges entirely on the accuracy of the list of prompts you choose.
No one can credibly claim that list represents what your buyers are actually asking. Some vendors claim privileged access to real prompt data harvested from real users. That data is biased, fragmented, and in many cases illegally obtained. The more common case is that the prompt set is a vendor's best guess at what buyers might type.
AI responses are hypersensitive to the phrasing and context of prompts. They also respond differently to identical prompts from different people. Running a set of prompts without user context does not give you insight into how the model is actually talking to your buyers.
The prompt set is a guess about their behavior, and share of voice is your performance on that guess.
Prompt tracking is fragile
I ran an experiment to test how stable share of voice is. I wrote 100 prompts about CRMs, the kind of thing a buyer might actually ask. "What's the best CRM?" "Which CRM is easiest to use for a 50-60 person sales team?" I ran them through AI models and recorded each brand's share of voice. Then I swapped exactly one word in each prompt with a synonym. I swapped "best" with "top," and "50-60" with "55". The meaning of the prompts was unchanged. The results surprised me.
The responses changed a lot. A single brand's share of voice moved by as much as 17% between the original prompts and the synonym-swapped version. 33% of the vendors in a typical answer changed identity. Only 16 of 100 prompt pairs produced identical vendor sets.
Profound, one of the proponents of share of voice, has published a related finding from their own data: 40–60% of the domains cited in AI responses change from one month to the next, even for identical prompts. They describe that as "volatility" that brands need to manage. A different reading is that a measure whose results swing by half on identical inputs means that the measurement framework is unstable.
The number of possible prompts is too big
The deeper issue is that the space of prompts your buyers could actually ask is combinatorially enormous, and much bigger than a search-era intuition would suggest. The average Google search is 3–4 words. The average ChatGPT prompt is 20+ words, and often considerably more.
That difference matters enormously when you start multiplying out possibilities. The number of potential ways you can ask a three-to-four-word search query is in the thousands. The number of potential ways you can ask a twenty-word prompt is greater than the grains of sand on Earth.
And that's just the first message. The average ChatGPT conversation is eight messages long. AI conversations are a sequence of prompts; each branches off the last and is shaped by context the model already has about the user. The number of potential conversations you can have with an AI is greater than the number of atoms in the universe.
Sampling 100 points from that space and calling it "share of voice" is closer to scooping 100 grains of sand from a beach and claiming you measured the beach.
It doesn't account for how people actually use AI
The multi-turn nature of AI conversations introduces another problem with share of voice. Even if you had a perfect prompt set, share of voice tracks the output of a single prompt, not the conversation as a whole.
The model's recommendation at question one is rarely its recommendation at question eight. By the time a buyer is close to a decision, the conversation has been refined, qualified, and reframed several times. Share of voice captures the first question. The decision happens later, in a conversation the metric was not designed to track.
It doesn't account for personalization
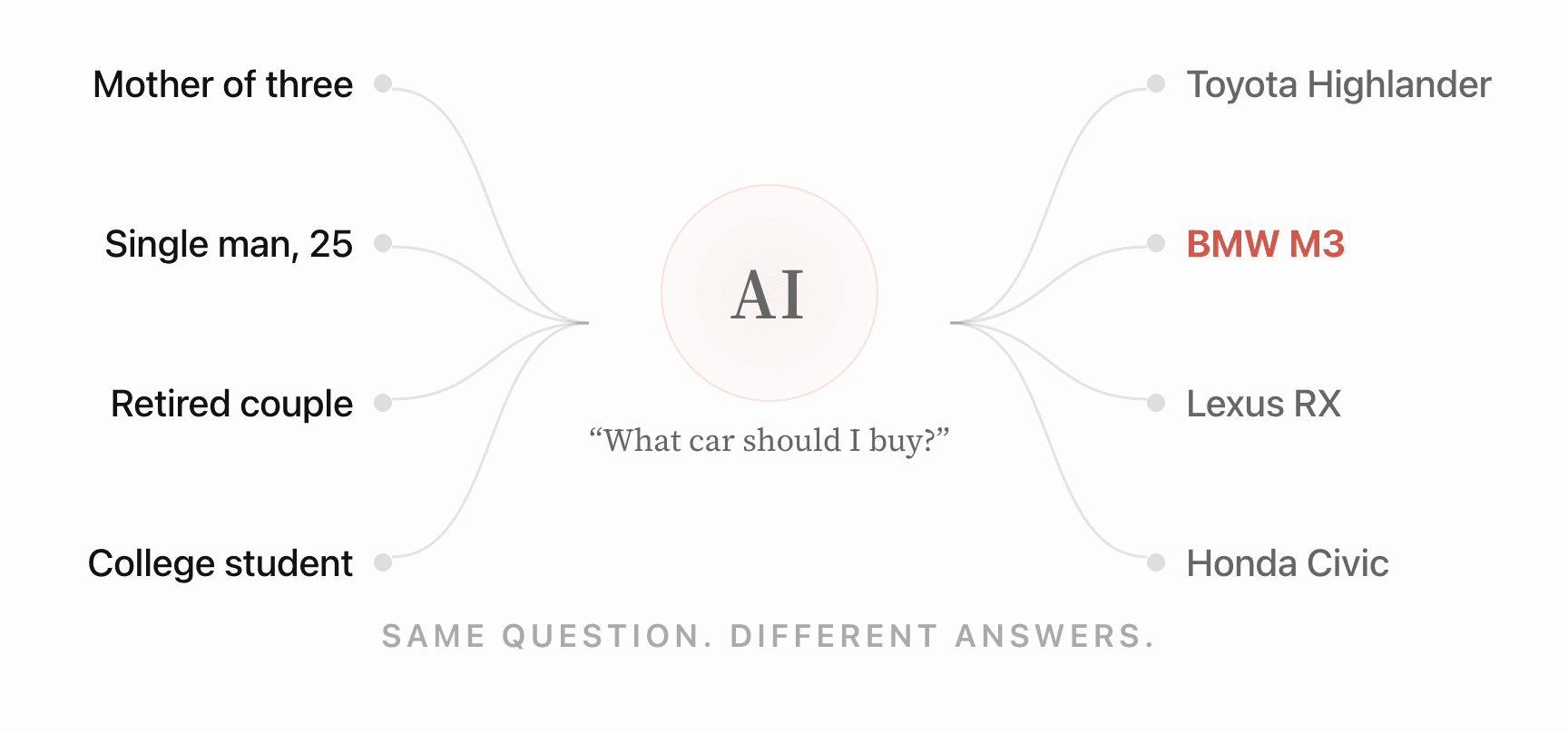
Within any single turn, there is no single "answer" to measure a share of. The same prompt from 100 different people yields 100 different responses, each shaped by what the model knows about the person asking: prior conversations, role, company, preferences, a constraint they mentioned last week. Two VPs of Sales asking the identical question receive materially different recommendations, because the model is drawing on a personalized picture of each of them.
Share of voice averages those responses into a single number. The assumption behind that average is that the distribution is uniform. It isn't. The distribution is shaped entirely by user context the tracking tool cannot see.
This is the Family Feud observation made concrete. When a system has no single answer to give, a metric that reports your share of "the answer" is reporting a fraction with no stable denominator.
What's worth measuring instead
The problem isn't unique to share of voice. Every rate-based metric in this category, citation rate, mention rate, visibility score, is a fraction against a hand-picked denominator, and inherits every issue above. Most of the movement brands pay to create on these metrics is on the same order as the movement a buyer generates for free by rephrasing a question.
What a marketer actually wants to know is different: what does the model believe about your brand, and how do those beliefs shift across the contexts your buyers actually bring? That answer is stable, specific, and tied closely enough to real buyer conversations to move pipeline.
Share of voice is hypersensitive to the prompts you pick. The model's picture of your brand is what your buyers meet. That's the layer underneath any rate based metric like share of voice. It's also the layer on which to build a strategy.